Big Data
Big Data is defined as a collection of large and complex data sets, mostly from disparate data sources that are difficult to store in classic databases or can be processed using traditional database techniques. It refers to amounts of data that are too large or too complex, or that change too quickly to be evaluated using manual and traditional methods of data processing. It’s not just about data volume and size; It is also about data usually being collected for a specific purpose and later evaluations often being made from a different perspective. The challenge is to derive correct insights from such complex and heterogeneous long-term data.
The following characteristics characterize Big Data:
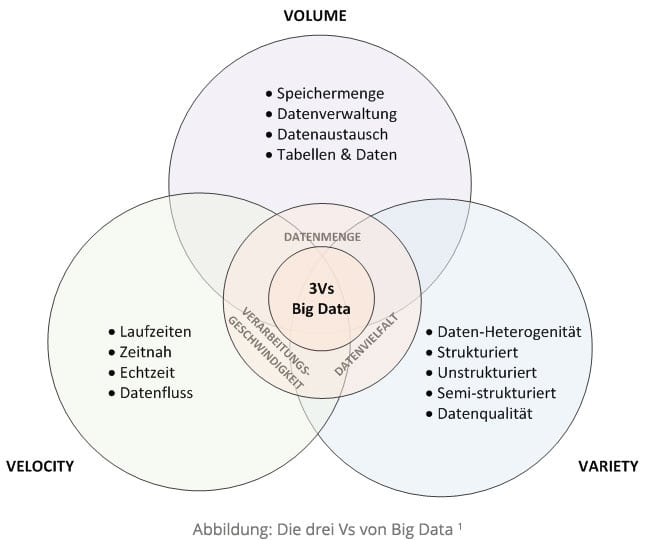
Volume – The vast amount of data in areas of several terabytes. With such large amounts of storage, data typically resides in virtualized clusters or in the cloud. The (storage) servers are controlled as needed within the IT infrastructure.
Variety – illustrates the heterogeneity in which the data is structured. The data mostly exists in different structure forms, formats and exists in different source systems. Since the data are “incorporated” by different people in the system, the “veracity” of the data, the so-called veracity from the point of view of uncertainty or inconsistency to question. An essential criterion for data diversity is therefore the quality of the data.
Velocity – describes the speed at which the data is processed and analyzed. Processing can be either timely or in real time. [1]
1 Source: oriented to Russom, 2011, p. 6